はじめに
前回までの記事で構築までの一連の手順を記載しました。あとは起動するだけですが、サービスの起動の順番を間違えると正常にサービス起動が出来ません。今回構築したZabbixはすべて手動起動を想定しているので、構成を理解していない人が触ると、トラブルにつながることでしょう。
本記事で紹介したZabbixサーバの構成での起動手順を紹介したいと思います。起動した後は、正常に停止する方法も紹介したいと思います。
※本手順にはどのサーバで実施するか記載していませんが、本番稼働用の手順書を作る場合は記載しておくと良いでしょう。
構成図
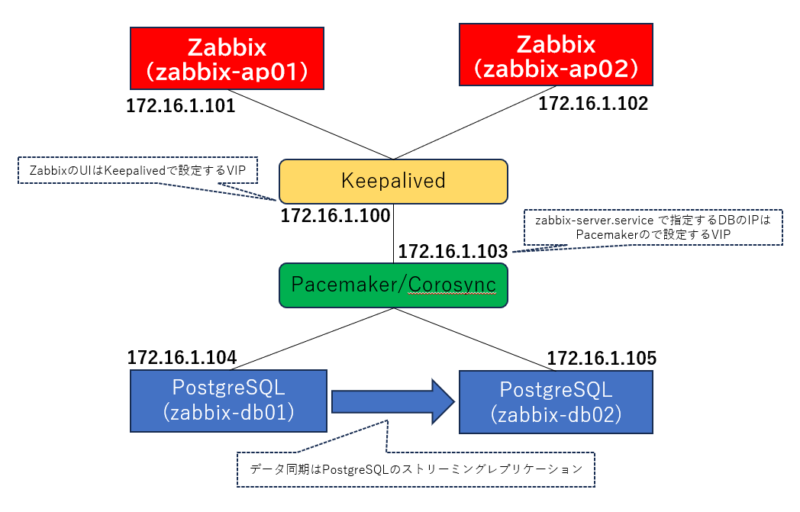
ホスト名:zabbix-ap01
IP:172.16.1.101
構成:AlmaLinux 9、Zabbix6.0
ホスト名:zabbix-ap02
IP:172.16.1.102
構成:AlmaLinux 9、Zabbix6.0
ホスト名:zabbix-db01
IP:172.16.1.104
構成:AlmaLinux 9、PostgreSQL 13
ホスト名:zabbix-db02
IP:172.16.1.105
構成:AlmaLinux 9、PostgreSQL 13
起動手順
起動の順序は以下の通りです。
1. DBの起動
2. Zabbix関連サービスの起動
3. Keepalivedサービスの起動
それぞれのサービス起動手順を確認します。それぞれのサービス起動時に正常に起動していないと、後続の起動に影響があるので、その都度サービスの起動状況の確認も行います。
DBの起動
DBを起動する場合、Pacemakerのサービスを起動します。直接DBの起動させないよう注意します。
レプリケーションされているか不明な場合、主系からコピーしてから起動させます。本手順では主系から副系にコピーする手順から記載しています。
主系DBの起動確認
主系DBを手動で起動します。当たり前ですが、この時点で起動しなければ、Pacemakerで起動しても失敗します。失敗時に切り分けしやすくするためにも、事前に確認することをおすすめします。
|
1 2 3 4 |
# su - postgres $ pg_ctl start done server started |
副系DBへのデータコピー
次に副系にDBをコピーします。すでに同期されている場合は不要ですが、障害発生時から復旧する場合などにはこの手順が必要となります。なお、予め$PGDATAのファイルは削除している必要があるので、実施前に削除しておきましょう。rootユーザで実行しないように注意してください。$PGDATAの所有者がrootになっている場合、DBの起動に失敗します。
|
1 2 |
# su - postgres $ pg_basebackup -D /var/lib/pgsql/13/data -h 172.16.1.104 |
PacemakerでDBを起動させるため、問題なく副系がコピーされた後に、主系のDBを停止させておきます。
|
1 2 3 |
$ pg_ctl stop waiting for server to shut down.... done server stopped |
なお、このときに副系DBの起動確認は行いません。Pacemakerで起動させてVIPを持たせるため、あくまでも手動で実施するのは「主系のDB起動確認」と「副系へのデータコピー」にとどめます。
PacemakerによるDBの起動
DBのコピーが完了したあと、PacemakerでDBを起動させます。先に起動させた方が主系となるため、起動の順番は運用方針に従って起動させてください。
|
1 2 3 4 |
$ exit logout # pcs cluster start Starting Cluster... |
DBの正常性確認
主系を起動した後、副系を起動する前に正常性確認をしておきましょう。主系DBが起動していない状況で副系のみが問題なく起動した場合、主副が逆になります。ポリシーに合わせるために主副を入れ替える必要が出た場合は、余計な作業が出来てしまうので、まずは主系のみで問題なく起動しているかを確認します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# pcs status --full Cluster name: zabbixdbCluster Status of pacemakerd: 'Pacemaker is running' (last updated 2024-06-03 14:21:10 +09:00) Cluster Summary: * Stack: corosync * Current DC: zabbix-db01 (1) (version 2.1.5-9.el9_2-a3f44794f94) - partition WITHOUT quorum * Last updated: Mon Jun 3 14:21:11 2024 * Last change: Mon Jun 3 07:16:14 2024 by root via crm_attribute on zabbix-db01 * 2 nodes configured * 5 resource instances configured Node List: * Node zabbix-db01 (1): online, feature set 3.16.2 * Node zabbix-db02 (2): OFFLINE Full List of Resources: * vip-master (ocf:heartbeat:IPaddr2): Started zabbix-db01 * Clone Set: pingChk-clone [pingChk]: * pingChk (ocf:pacemaker:ping): Started zabbix-db01 * pingChk (ocf:pacemaker:ping): Stopped * Clone Set: prmPostgresql-clone [prmPostgresql] (promotable): * prmPostgresql (ocf:heartbeat:pgsql): Promoted zabbix-db01 * prmPostgresql (ocf:heartbeat:pgsql): Stopped <span class="marker-red">Node Attributes:</span> * Node: zabbix-db01 (1): * master-prmPostgresql : 1000 * pingattr : 1 * prmPostgresql-data-status : LATEST * prmPostgresql-master-baseline : 00000000480000A0 * prmPostgresql-status : PRI Migration Summary: Tickets: PCSD Status: zabbix-db01: Online zabbix-db02: Online |
確認箇所は「Node Attributes」の部分で、「-INFINITY」や「DISCONNECT」値が出てしまっている場合は正常に稼働していない状況です。
問題なく起動できていることを確認したら、副系も同様に起動します。両方とも起動できた場合、以下のような結果になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
# pcs status --full Cluster name: zabbixdbCluster Status of pacemakerd: 'Pacemaker is running' (last updated 2024-06-03 14:39:00 +09:00) Cluster Summary: * Stack: corosync * Current DC: zabbix-db01 (1) (version 2.1.5-9.el9_2-a3f44794f94) - partition with quorum * Last updated: Mon Jun 3 14:39:00 2024 * Last change: Mon Jun 3 14:38:53 2024 by root via crm_attribute on zabbix-db01 * 2 nodes configured * 5 resource instances configured Node List: * Node zabbix-db01 (1): online, feature set 3.16.2 * Node zabbix-db02 (2): online, feature set 3.16.2 Full List of Resources: * vip-master (ocf:heartbeat:IPaddr2): Started zabbix-db01 * Clone Set: pingChk-clone [pingChk]: * pingChk (ocf:pacemaker:ping): Started zabbix-db01 * pingChk (ocf:pacemaker:ping): Started zabbix-db02 * Clone Set: prmPostgresql-clone [prmPostgresql] (promotable): * prmPostgresql (ocf:heartbeat:pgsql): Promoted zabbix-db01 * prmPostgresql (ocf:heartbeat:pgsql): Unpromoted zabbix-db02 Node Attributes: * Node: zabbix-db01 (1): * master-prmPostgresql : 1000 * pingattr : 1 * prmPostgresql-data-status : LATEST * prmPostgresql-master-baseline : 000000004C000060 * prmPostgresql-status : PRI * Node: zabbix-db02 (2): * master-prmPostgresql : 100 * pingattr : 1 * prmPostgresql-data-status : STREAMING|SYNC * prmPostgresql-status : HS:sync Migration Summary: Tickets: PCSD Status: zabbix-db01: Online zabbix-db02: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled |
実は本記事を書くために検証環境のDBを起動させた際も、エラーが出て起動できなかったため、ログを追いました。PacemakerかPostgreSQLのログのいずれかにヒントがあると思うので、エラーの際はログを追って解決してみてください。
IP確認
VIPが想定通りに付与されているか確認してみましょう。主系に「172.16.1.103」が付与されています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:0c:29:18:75:9d brd ff:ff:ff:ff:ff:ff altname enp11s0 inet 172.16.1.104/24 brd 172.16.1.255 scope global noprefixroute ens192 valid_lft forever preferred_lft forever inet 172.16.1.103/24 brd 172.16.1.255 scope global secondary ens192 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:fe18:759d/64 scope link noprefixroute valid_lft forever preferred_lft forever |
Zabbix関連サービスの起動
Zabbix関連と書いたのは、Zabbixサーバ以外にもhttpd、php-fpmといったサービスの起動も必要です。
正直DB起動まで問題なくできれば、これ以降のZabbix関連のサービス確認は割と容易にできるかと思います。
Zabbixサーバ、httpd、php-fpm、Zabbixエージェントサービスの起動
以下のコマンドでサービスを起動します。
|
1 |
# systemctl start zabbix-server.service zabbix-agent.service httpd.service php-fpm.service |
各サービスの状態確認
以下のコマンドを実行して、アクティブになっていることを確認します。以下はzabbix-server.serviceの確認です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# systemctl status zabbix-server.service ● zabbix-server.service - Zabbix Server Loaded: loaded (/usr/lib/systemd/system/zabbix-server.service; disabled; preset: disabled) Active: <span class="marker-red">active (running)</span> since Tue 2024-06-04 09:56:28 JST; 6min ago Process: 2887 ExecStart=/usr/sbin/zabbix_server -c $CONFFILE (code=exited, status=0/SUCCESS) Main PID: 2900 (zabbix_server) Tasks: 102 (limit: 11124) Memory: 107.2M CPU: 1.233s CGroup: /system.slice/zabbix-server.service tq2900 /usr/sbin/zabbix_server -c /etc/zabbix/zabbix_server.conf tq2916 "/usr/sbin/zabbix_server: ha manager" … |
問題なく主系を起動出来たら、副系も起動します。
Zabbix HA の状態確認
先に起動した方がHAのActiveになっています。以下のコマンドで確認します。ap01がactiveになっていることを確認できます。
|
1 2 3 4 5 6 |
# zabbix_server -R ha_status Failover delay: 60 seconds Cluster status: # ID Name Address Status Last Access 1. clmdf5vzx00012y0eomes62y2 zabbix-ap01 172.16.1.101:10051 active 0s 2. clmdg2uxt0001lp0fuu3da1zm zabbix-ap02 172.16.1.102:10051 standby 1s |
Keepalivedの起動
最後にKeepalivedサービスを起動します。こちらも起動に順に応じて主副が決定されます。
以下のコマンドで起動します。
|
1 |
# systemctl start keepalived.service |
以下のコマンドで起動状態を確認し、アクティブになっているか確認します。
|
1 2 3 4 5 6 7 8 9 10 11 |
# systemctl status keepalived.service ● keepalived.service - LVS and VRRP High Availability Monitor Loaded: loaded (/usr/lib/systemd/system/keepalived.service; disabled; preset: disabled) Active: active (running) since Tue 2024-06-04 10:04:23 JST; 14s ago Main PID: 3427 (keepalived) Tasks: 2 (limit: 11124) Memory: 6.9M CPU: 9ms CGroup: /system.slice/keepalived.service tq3427 /usr/sbin/keepalived --dont-fork -D mq3428 /usr/sbin/keepalived --dont-fork -D |
IPも確認しておきましょう。以下は主系で実行した結果です。「172.16.1.100」が付与されています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:0c:29:47:7e:f6 brd ff:ff:ff:ff:ff:ff altname enp11s0 inet 172.16.1.101/24 brd 172.16.1.255 scope global noprefixroute ens192 valid_lft forever preferred_lft forever inet 172.16.1.100/32 scope global ens192 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:fe47:7ef6/64 scope link noprefixroute valid_lft forever preferred_lft forever |
問題なく起動出来たら、副系でも起動します。
これで起動は完了です。ブラウザでZabbixのGUI画面にアクセスできると思います。
停止手順
サービスを停止する手順は以下の通りです。
1. Keepalivedの停止
2. Zabbix関連サービスの停止
3. DBの停止
停止は起動とは逆の順序で、副系を停止後に主系も停止します。当然と言えばそれまでですが、手動起動のシステムを構築した場合は明確にしておきましょう。運用担当者が停止手順を間違えて、起動時にトラブルになることは避けたいところです。
Keepalivedの停止
以下のコマンドで停止します。※副系から先に停止します。
|
1 |
# systemctl stop keepalived.service |
起動時と同じコマンドで停止できているか確認します。
|
1 2 3 4 |
# systemctl status keepalived.service ○ keepalived.service - LVS and VRRP High Availability Monitor Loaded: loaded (/usr/lib/systemd/system/keepalived.service; disabled; preset: disabled) Active: inactive (dead) |
Zabbix関連サービスの停止
以下のコマンドで停止します。副系を停止後、主系を停止します。
|
1 |
# systemctl stop zabbix-server.service zabbix-agent.service httpd.service php-fpm.service |
同様に、サービスの状態を確認します。
|
1 2 3 4 |
# systemctl status zabbix-server.service ○ zabbix-server.service - Zabbix Server Loaded: loaded (/usr/lib/systemd/system/zabbix-server.service; disabled; preset: disabled) Active: inactive (dead) |
DBの停止
副系のDBを停止します。以下のコマンドを実行します。
|
1 2 3 |
# pcs cluster stop Stopping Cluster (pacemaker)... Stopping Cluster (corosync)... |
停止後、ステータスを確認します。
|
1 2 |
# pcs cluster status Error: cluster is not currently running on this node |
問題なく停止できた後、主系のDBを停止させます。
主系停止時は「–force」オプションを付与します。
|
1 2 3 |
# pcs cluster stop --force Stopping Cluster (pacemaker)... Stopping Cluster (corosync)... |
以上が起動から停止までの手順です。
同じ構成で構築されていることは少ないかもしれませんが、部分的に活用できる場面があれば幸いです。